NLP中的Tokenizer分词器的概念与实现 |
您所在的位置:网站首页 › nlp 分词技术 › NLP中的Tokenizer分词器的概念与实现 |
NLP中的Tokenizer分词器的概念与实现
|
Tokenizer
在开始学习 NLP 相关知识之前,先要学习一个叫 Tokenizer 的概念,这可谓是所有 NLP 模型开始训练前需要做的一个步骤,那么 Tokenizer 是什么?
在计算机处理一行语句的时候,我们给其输入一个 String,计算机实际上是很难进行处理的,所以我们希望把这么一个 String,把他的每一个字或者每一个词切分开,并且转换成一个数字(用数字来进行表示),也就是一个 ID。 Tokenizer 翻译过来叫切词器,其所做的事情就是这么一个事情。 如上图所示,有一个 String:“站在人生的龍字路口,不知所措”。 然后将其按字切开,得到:“ 站 在 人 生 的 龍 字 路 口 , 不 知 所 措 ”。 然后就应该进行查表了,应该会存在这么一个类似于字典的东西,该字典包含了很多常见的字或者是词,对于表中不存在的字词会使用一个特殊的标识 UNK 来进行表示。 最后将这些 token 转换成一个 int,也就是刚刚说的 ID。 这个说白了就是一个切词工具,因此我们不会自己写一个字典,直接引入 Hugging Face 已经写好的分词器训练模型,使用该模型训练一个分词器出来使用即可,Hugging Face 网页的链接如下: Hugging Face 提供的 Tokenizer 工具; 点击链接进去可以发现如下:
使用 pip install tokenizers 命令即可进行下载,如果下载过程出错,那么就多下载几次,我也是第三次下载的时候一下就下载好了,突然的非常快我也不知道为什么,反正多试几次。 这里需要一个语料库,我是直接在百度上找了一本 txt 格式的小说文本放进代码中充当语料库了,如果你要使用的话应该也能这么做,百度搜索 “小说txt文件” 应该就能像我一样找到。
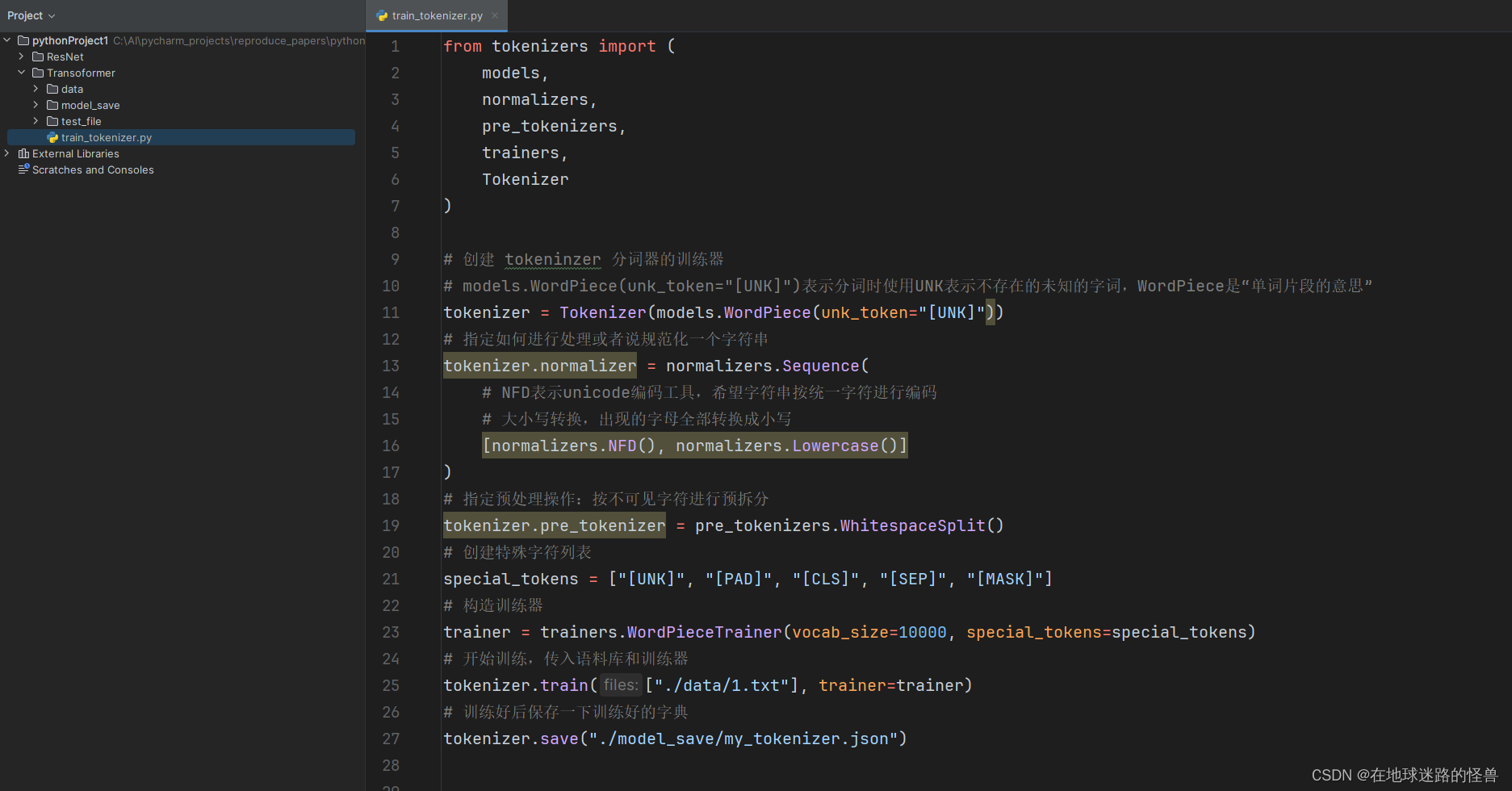
然后写上训练代码,用来训练我们的 tokenizer 分词器:
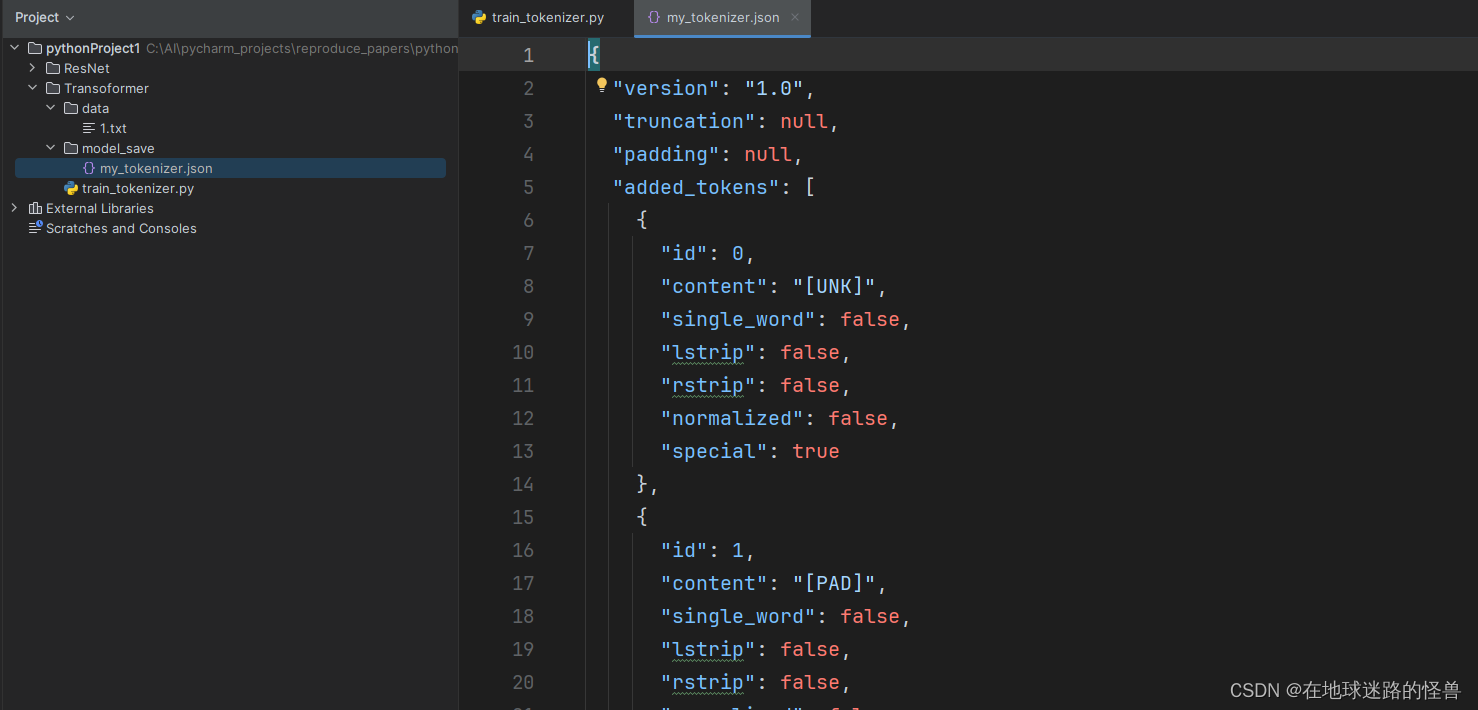
这里如果报错 Exception: stream did not contain valid UTF-8 ,将 txt 文件重新保存为 UTF-8 编码的形式即可。 运行之后在我们的 model_save 文件夹下出现一个 json 文件:
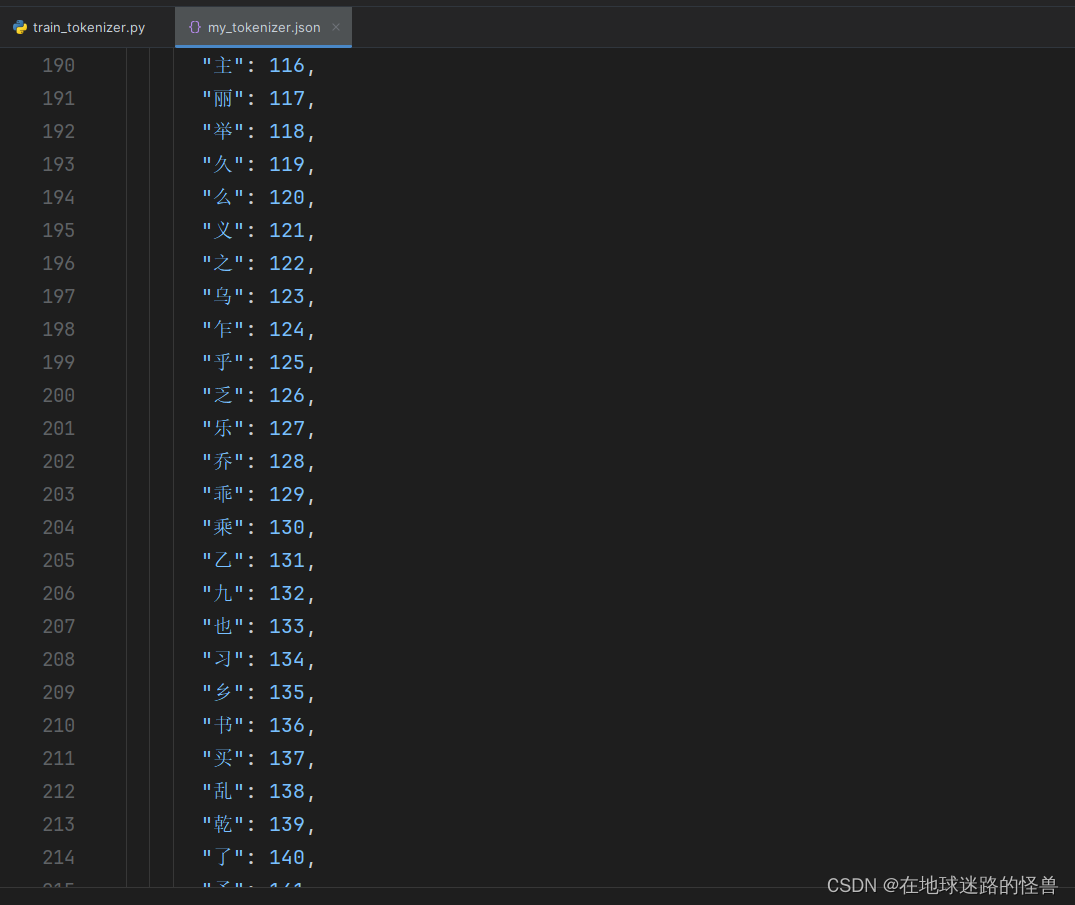
往下拉可以看到已经都分好各个词或者字的 ID 啦:
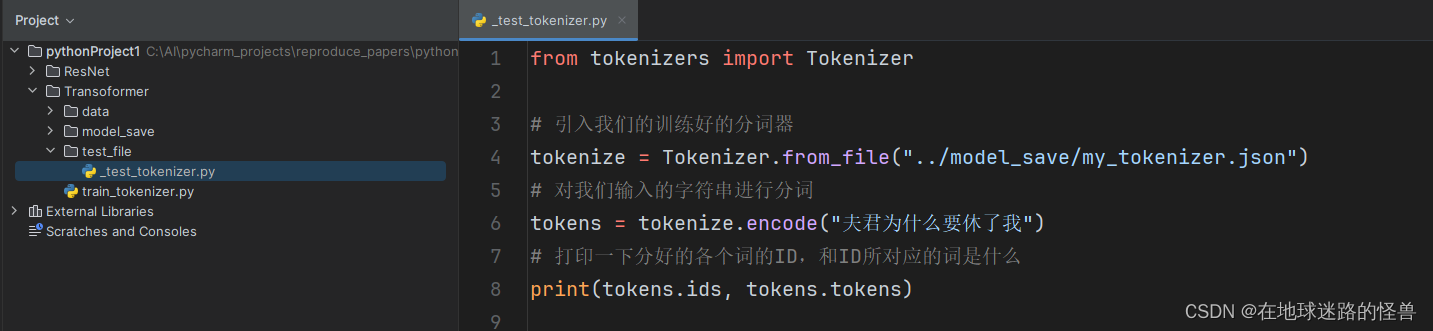
接下来进行一个测试:
分词结果如下:
可以看见各个词或者字都被切了出来,并且都各自拥有一个在训练过程中被分配好的 ID 值。 ##开头的词是什么意思? ##开头表示这个词或者字不是一个完整的词或者字,其是一个词根(因为分词器啥语言都能分,这里我们使用的中文,因此其也有一个对应的所谓词根的操作),为了节省内存空间,tokenizer 会把一些常见词拆成更零碎的部分,通过这些更零碎的部分则可以拼接出更多的词来提高切词的成功率。 上述就是在自然语言处理中所经常使用的 Tokenizer 的概念与简单实现。 |



【本文地址】
今日新闻 |
推荐新闻 |